

清蒸萌新literal @[email protected]
- 状态
- 人生失败哩!
- 个人网站
- (已经下线)
- 爱好
- 编程
- 妄想
- 成为美少女
莉特雅 literal
写代码业余爱好者 amateur coder
Joined Jan 2020
折腾脚本(雾)
拿 ip 地址
DEV="enp0s3"
# ipv4
ip address show dev ${DEV} | grep -P 'inet(?!6)' | cut -d ' ' -f 6
# -f 8 是广播地址
# ipv6
ip address show dev ${DEV} | grep -P 'inet6' | cut -d ' ' -f 6
# -f 到底是多少挺坑的
os-release NAME
cat /etc/os-release | grep '^NAME=' | cut -d = -f 2 | grep -o '[^"]*'
Reading Project - 康康 scrapy 的 response.css 怎么实现的
起因
今天喝水多,头脑比较清醒,从官网的例子里看到了这个:
import scrapy
class BlogSpider(scrapy.Spider):
name = 'blogspider'
start_urls = ['https://www.zyte.com/blog/']
def parse(self, response):
for title in response.css('.oxy-post-title'):
yield {'title': title.css('::text').get()}
for next_page in response.css('a.next'):
yield response.follow(next_page, self.parse)
其中 response.css 不禁让我感叹,我要是早点知道这玩意能这么搞,我还html5lib.parse个锤子。
发掘
经过一番我已经记不起来的搜索,从 response 和 css 关键字,用 github 在仓库内搜索便可以找到这里:
def css(self, *a, **kw):
"""Shortcut method implemented onlyby responses whose content
is text (subclasses of TextResponse).
"""
raise NotSupported("Response contentisn't text")
同一个文件夹下有一个 text.py 可以找到这里:
def css(self, query):
return self.selector.css(query)
同一个类中,找到 selector 的实现:
@property
def selector(self):
from scrapy.selector import Selector
if self._cached_selector is None:
self._cached_selector = Selector(self)
return self._cached_selector
从 from...import 语句可以看出该进入包 scrapy.selector:
from scrapy.selector.unified import Selector, SelectorList
找到 Selector 类的定义:
class Selector(_ParselSelector, object_ref):
然后去找 _ParselSelector 类就可以看到这个:
from parsel import Selector as _ParselSelector
就能确定转发给了软件包parsel。
进一步还能确定parsel进一步转发了cssselect。
结论
scrapy -> parsel -> cssselect
大致思路是css选择器转换为xpath再交给lxml跑。
不知道隔了多久,重新读了一下自己的代码
二义性验证器(雾)
"""简单文法推导 & 二义性检查器
文法:
S -> iS | M
M -> iMeS | O
-----
记号:
S = statement, M = matched_statement, O = other
i = if, e = else
"""
import copy
class Obj:
"""储存推导路径的定制对象
Attributes:
value: 当前值
path: 推导路径
"""
def __init__(self, init):
self.value = init # 当前值
self.path = [] # 推导路径
self.path.append(init)
def push(self, ns):
"""推导
指定推导并加入推导路径
Args:
ns: 新推导出的短语
"""
self.value = ns
self.path.append(ns)
def __repr__(self):
return self.value
# 重载相等性判断
def __hash__(self):
return hash(self.value)
def __eq__(self, other):
return self.value == other.value
# 推导用到的结构
cur = [Obj('S')] # 当前值 | 初始值
nxt = [] # 被推导出的临时值
# 所有推导结果
# 用来检查二义性
ahs = set()
ahl = []
# 检查二义性检查有效
assert(Obj('SS') == Obj('SS'))
assert(Obj('SS') != Obj('SSb'))
def cfind(s : str):
"""查找文法变量(非终结符)
"""
spos = s.find('S')
mpos = s.find('M')
if spos == -1 and mpos == -1:
return 'O'
if spos == -1:
return 'M'
if mpos == -1:
return 'S'
if spos < mpos:
return 'S'
else:
return 'M'
# main -------------------------------------------------------------------------
for i in range(100):
# 推导
for mem in cur:
svar = cfind(mem.value)
if svar == 'S':
# 1
prod1 = copy.deepcopy(mem)
prod1.push(prod1.value.replace('S', 'iS', 1))
nxt.append(prod1)
# 2
prod2 = copy.deepcopy(mem)
prod2.push(prod2.value.replace('S', 'M', 1))
nxt.append(prod2)
elif svar == 'M':
# 1
prod1 = copy.deepcopy(mem)
prod1.push(prod1.value.replace('M', 'iMeS', 1))
nxt.append(prod1)
# 2
prod2 = copy.deepcopy(mem)
prod2.push(prod2.value.replace('M', 'O', 1))
nxt.append(prod2)
ahl.extend(nxt) # 推导出的 nxt 加入 all history list
# 查找二义性冲突 并更新 set
for nmem in nxt:
# 在 all history set 中查找相同的推导结果
# 如果找到二义结果才执行整个 if
if nmem in ahs:
# 在 ahl 里找所有重复推出的短语
# NOFIXME: 是不是应该先找在把 nxt 加入 ahl,不然如果列表顺序乱了不就输出两个一毛一样的
# FIXNMB: 这里是打印所有的重复项
for s in ahl:
if s == nmem:
print(s.path) # 打印重复项
ahs.add(nmem)
# 交互式控制一轮轮推导
print(i+1)
input('next>')
cur = nxt
nxt = []
所以说搞标签化不是蠢就是坏,还能又蠢又坏
https://hello.2heng.xin/@line/106186064069280006
无聊之fuzz spec:
#include <stdio.h>
#include <stdlib.h>
#include <limits.h>
int main()
{
int a;
int b;
for(unsigned long long count = 0; count < ULLONG_MAX; ++count)
{
a = rand();
b = min(1, rand()); // b 不能是 0
printf("\rcheck for %llu random number", count);
// printf("%d %d\n", a, b);
if( ( (a/b) * b + a % b ) != a )
printf("\nunequal for {a = %d, b = %d}\n", a, b);
}
return 0;
}
至今无一例外
(a/b)*b+a%b shall equal to a
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char **argv)
{
int a;
int b;
if (argc < 3)
exit(1);
// atoi(str) equal to (int)strtol(str, NULL, 10)
a = (int)strtol(argv[1], NULL, 10);
b = (int)strtol(argv[2], NULL, 10);
printf("a = %d ; b = %d\n", a, b);
printf("a/b = %d ; a %% b = %d\n", a/b, a%b);
printf("(a/b)*b+a%%b = %d\n", (a/b)*b+a%b);
return 0;
}
> a -500 -91
a = -500 ; b = -91
a/b = 5 ; a % b = -45
(a/b)*b+a%b = -500
1202年,我们仍然享受着人上人对我们的折磨。
#学校那些事 我比较后悔的事情就是跟同学说我会计算机。我还算运气好的,我们老师大多得知后给我提供机会,建议我去参加比赛。而我的网友就没那么好的运气了,他被偏见所折磨。比如周围人会认为他有关计算机的一切都会,再比如校领导想白嫖他,而且任务量不可思议。
如果一个国家的孩子说大人话办大人事,这个国家的大人准说孩子话办孩子事。
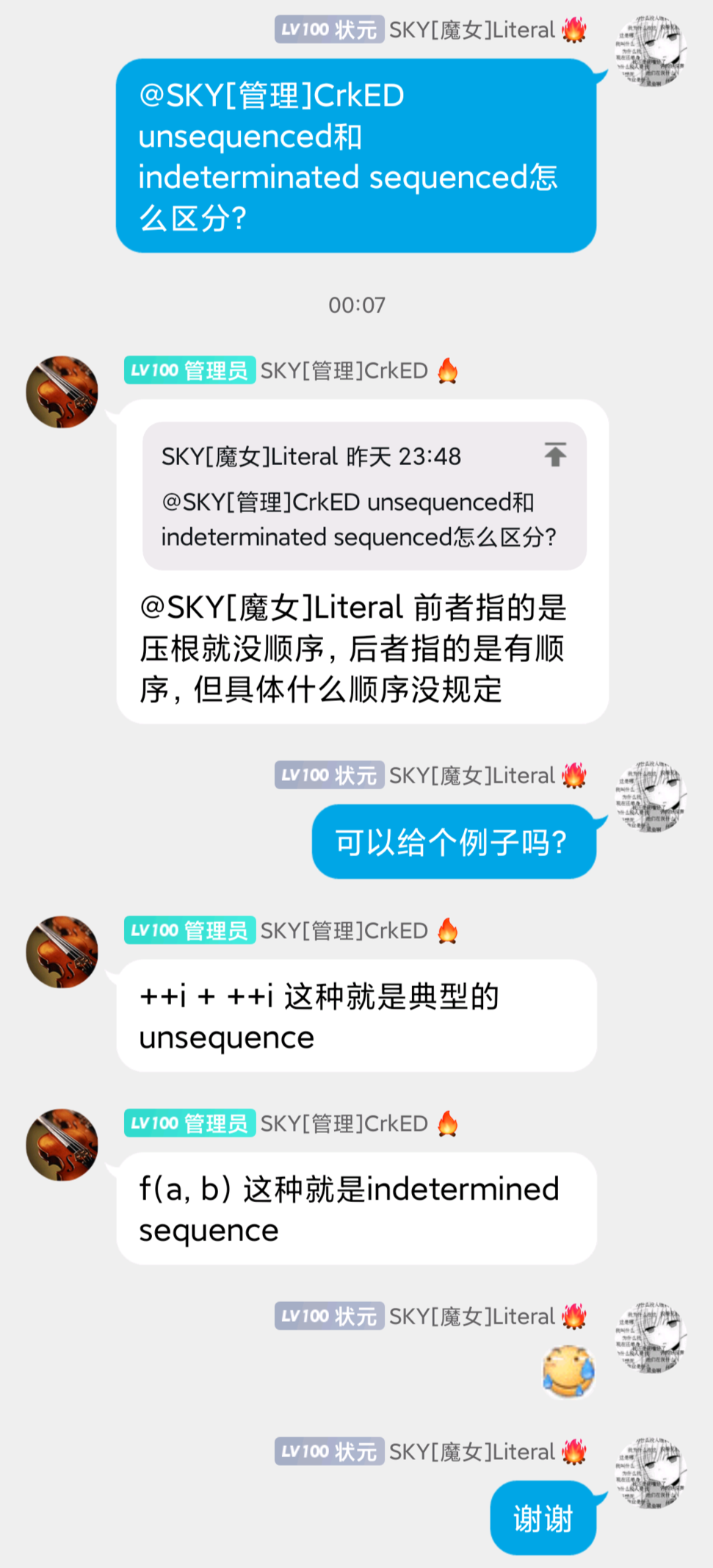
A is sequemced either before or after B, but it is specified which.
Indeterminately sequenced evaluations cannot interleave, but can be executed in any order.
那差不多意思应该是求值是sequenced的,但是seqence之间的顺序不确定。
清蒸萌新literal
boosted

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
短视频把这届观众给害了
QT: [https://9kb.me/@chouti/106112066652502040]
【被这届观众“嫌弃”的《指环王》】在2004年内地上映时,三部《指环王》连映是不少影院的卖点。媒体曾经联合影院和电影公司举办“《指环王》连映超级耐力挑战赛”,有125名选手参与了长达9小时的马拉松观影,最终有一半以上的人留在了结束一刻。
https://dig.chouti.com/link/30772313
{kind=link}
- 状态
- 人生失败哩!
- 个人网站
- (已经下线)
- 爱好
- 编程
- 妄想
- 成为美少女
莉特雅 literal
写代码业余爱好者 amateur coder
Joined Jan 2020
