

一直没写简介是因为我实在不知道该写啥
脑子空荡荡🙉
Joined Nov 2020
蜂蜜芥末  boosted
boosted

#必应每日一图 库赫莫附近暴风雪中的乌鸦,芬兰 (© Frans Lemmens/Alamy)![]() https://u.2heng.xin/sEkvGT
https://u.2heng.xin/sEkvGT
蜂蜜芥末
boosted

分享 GitHub 上一个智能 Web 爬虫脚本。
其主要作用,是能快速且智能获取指定网站上的数据,这些数据可以是网页文本、url 地址或者其它 HTML 元素。
该脚本兼容 Python3,使用简单便捷,让你可从此告别爬虫手动解析网页及写规则的烦恼。
GitHub: ![]() 网页链接
网页链接
蜂蜜芥末
boosted

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
@233mc44 抱抱你,只要熬过这段时间,就会发现这些其实都不是啥大事啦!至少下次就不会错啦! ![]()
@Kni 哇加油!!
蜂蜜芥末
boosted
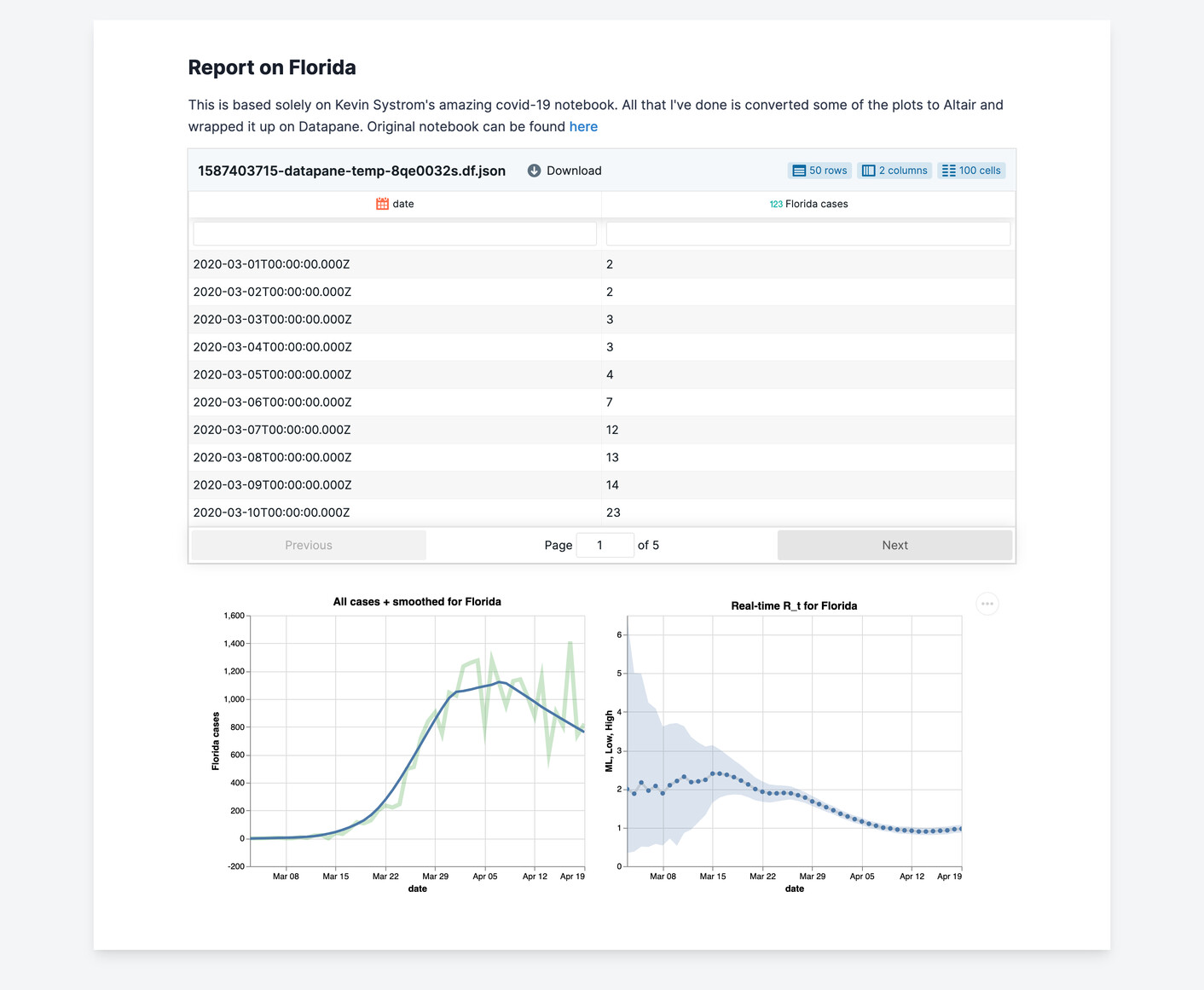
推荐个比较实用的 Python 开源库:Datapane,开发者可用它快速从常见对象(如 pandas DataFrames)上快速构建数据分析报告。
每个报表均可作为独立 HTML 文件导出,其中包含各类丰富组件,这些组件都可以进行数据浏览与可视化交互。
GitHub: ![]() 网页链接
网页链接
{kind=link}
@apatite 哈哈哈主要是 我连选项都想不出来!(完全没想法没胃口 ![]() )所以刚刚已经在外卖平台随便点了一份了
)所以刚刚已经在外卖平台随便点了一份了 ![]()
好难 不知道晚上吃些什么好 ![]()
{kind=link}
蜂蜜芥末
boosted
{kind=link}
{kind=link}
{kind=link}
{kind=link}
或许 大家觉得
另一个伊甸:超越时空的猫
好玩吗
(国服好像昨天公测的!我有点感兴趣)
{kind=link}
{kind=link}
{kind=link}
蜂蜜芥末
boosted
为了更为方便且直观的展示自己的跑步信息,一位名为伊洪的开发者在 GitHub 上开源了一个项目:Running Page。
该项目通过 GitHub Actions + Gatsby 自动完成跑步进程的同步管理,并生成一个直观简洁的跑步界面,让用户可以更为方便的记录自己在不同时段、不同日期的跑步频率与旅程。
GitHub: ![]() 网页链接
网页链接
{kind=link}
{kind=link}
@mashiro 这么难的吗! ![]()
阿里云盘的邀请码怎么搞啊 自己去哪申请吗 还是用户邀请制啊 ![]()
@[email protected] 我试完回来啦!我是最新系统 它给我随意画的巨丑的猫取名叫“灬” 我很不解
@[email protected] omg真的吗!我去试试 ![]()
和自己打一个没有别人知道的赌 ![]()
一直没写简介是因为我实在不知道该写啥
脑子空荡荡🙉
Joined Nov 2020
