You want to reply to this post:

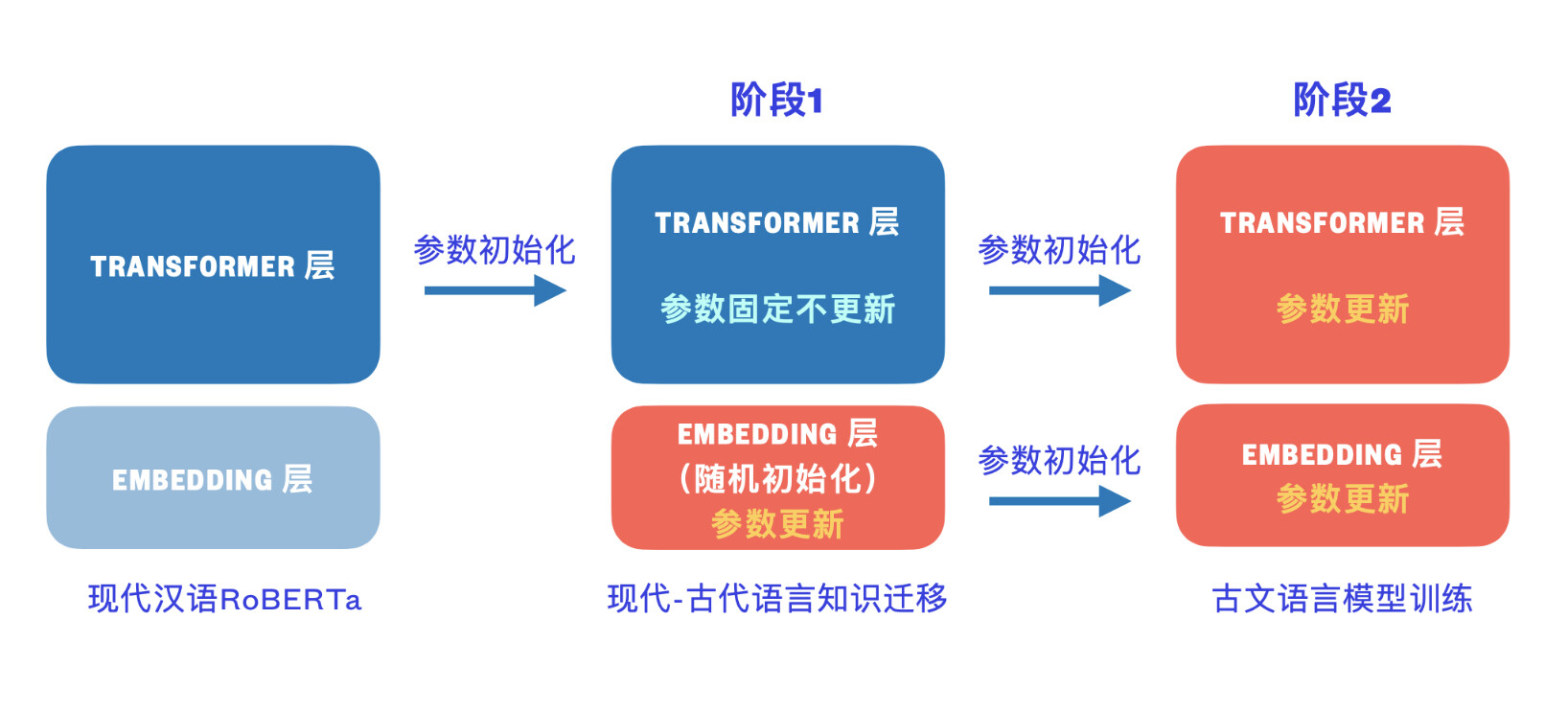
为了进一步促进古文研究和自然语言处理的结合,来自北京理工大学的 Ethan 及其团队成员发布了古文预训练模型 GuwenBERT。
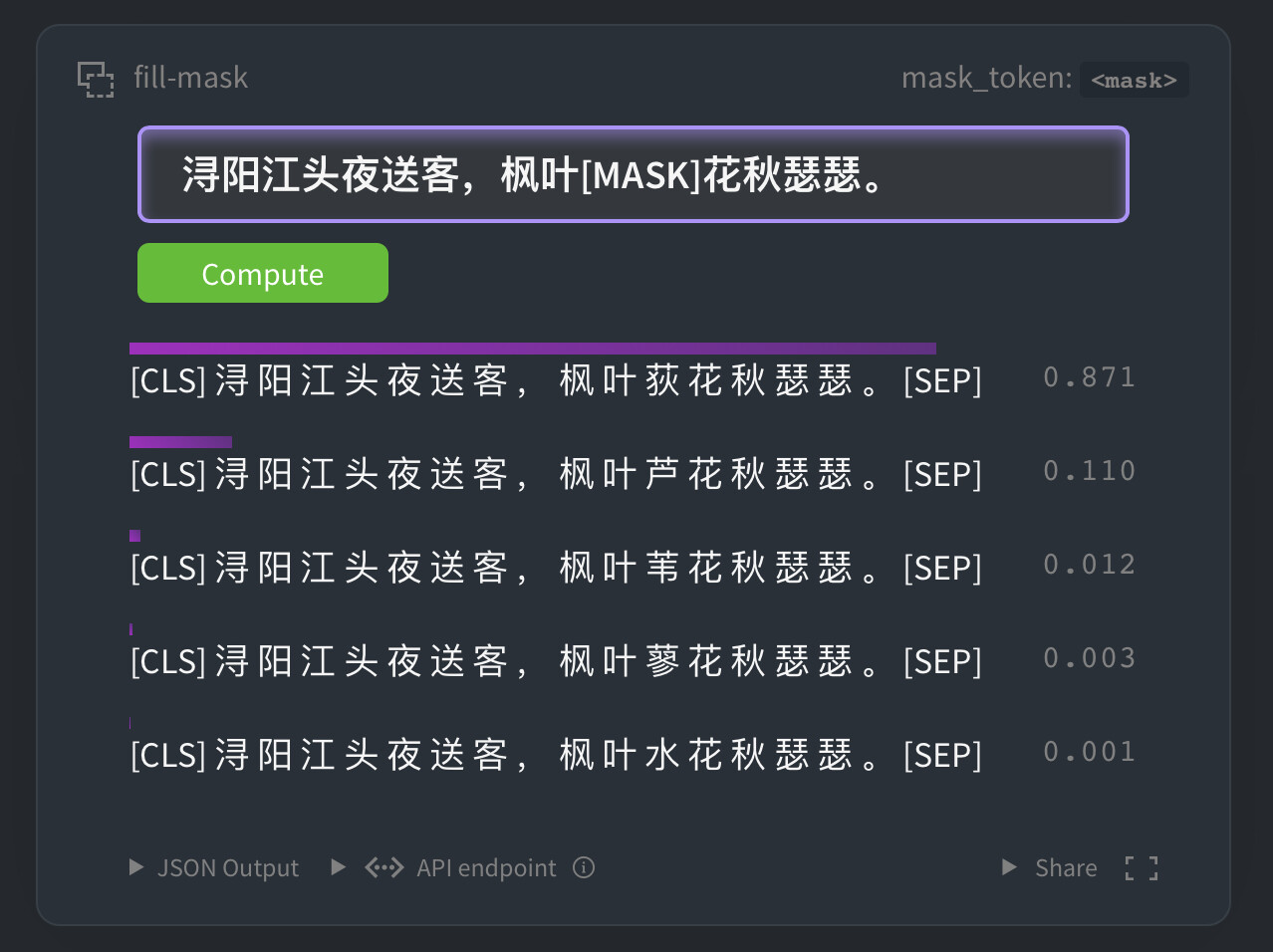
在古文 NER 任务中,该项目 BERT 比目前最流行的中文 RoBERTa 效果提升 6.3%,特别适合标注语料不足的小数据集。
另外,使用这一模型,也可以减少数据清洗,数据增强,引入字典等繁琐工序。
GitHub: ![]() 网页链接
网页链接
为了进一步促进古文研究和自然语言处理的结合,来自北京理工大学的 Ethan 及其团队成员发布了古文预训练模型 GuwenBERT。
在古文 NER 任务中,该项目 BERT 比目前最流行的中文 RoBERTa 效果提升 6.3%,特别适合标注语料不足的小数据集。
另外,使用这一模型,也可以减少数据清洗,数据增强,引入字典等繁琐工序。
GitHub: ![]() 网页链接
网页链接

{kind=link}
{kind=link}
{kind=link}